ML,
without the FML
Open source platform for machine learning dev environments. SSH into GPU machines across cloud providers.
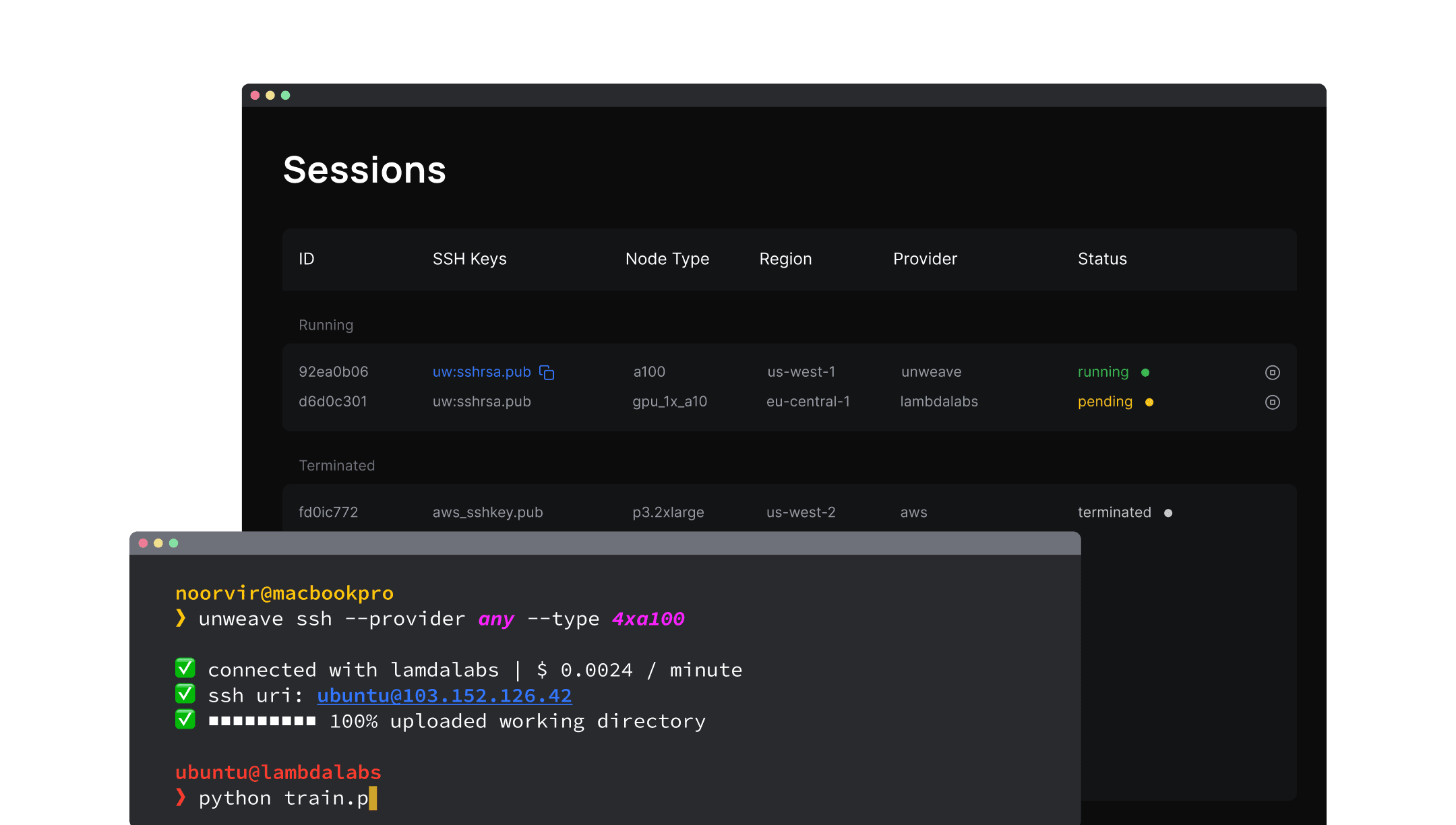



Get started in seconds
Get up and running with an ML environment on an instance of your choice
1. Install
$ brew install unweave/unweave/unweave2. Initialize
$ unweave link <project-id>3. Connect
$ unweave ssh --provider unweave --gpu-type a100_x4
Choose your provider:
Choose your runtime:
Transparent Cloud Costs*
Unweave converts cloud provider spaghetti pricing into something parseable by mere mortals
Unweave
LamdaLabs
More coming soon ...
*We update the exact pricing per provider at runtime. We do not charge a mark up on pricing of cloud providers. Unweave is free to get started by bringing your own cloud provider.
See here for the platform pricing.
Defaults that just work
Unweave chooses sane defaults that just work, while letting you tweak to your heart's content.
Run from your terminal
A cross platform CLI that fits your workflow whether locally or in a browser IDE. It works just as well in CI/CD pipelines.
Manage from the Browser
The Unweave Dashboard gives you a convenient realtime view of your projects and sessions.
Zero setup remote GPUs
Who want's to configure cloud infra when you could doing `model.fit()`. Unweave sets up your cloud dev environment for you.
Work across cloud providers
GPUs are in short supply. What if you could search across cloud providers for the best price and availability?
Sync code and data with Git
(Coming soon) Automatically version your code, data and artifacts with Git, with inbuilt CI/CD integrations.
Clone code and data seamlessly
(Coming soon) Start ML experiments directly from your Git repo. Unweave will automatically clone your code and data.
Built for flexibility
Develop with tools you're already used to. Unweave is built on top of plain old SSH and Git.
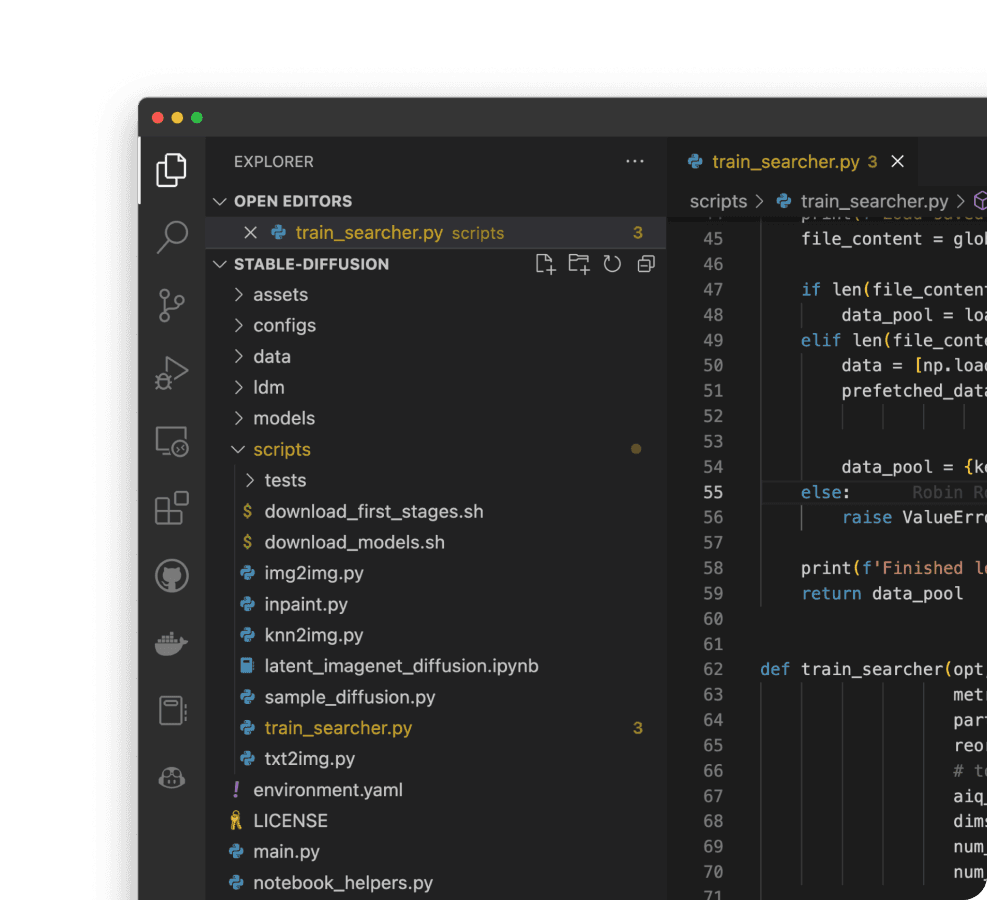
Your code editor
Write code in the IDE you're already used to. Whether on your local laptop or in a browser IDE. Unweave
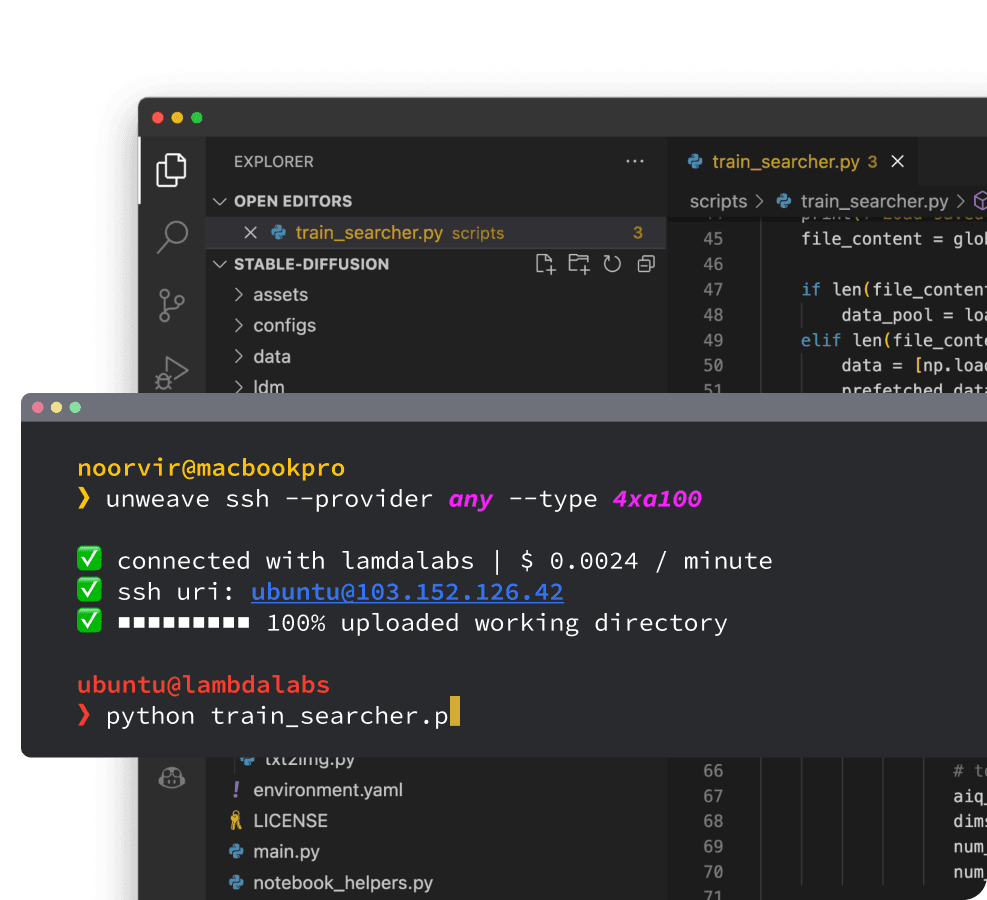
Unweave CLI
Setup dev environment that integrate with your IDE straight from your terminal with the Unweave CLI.
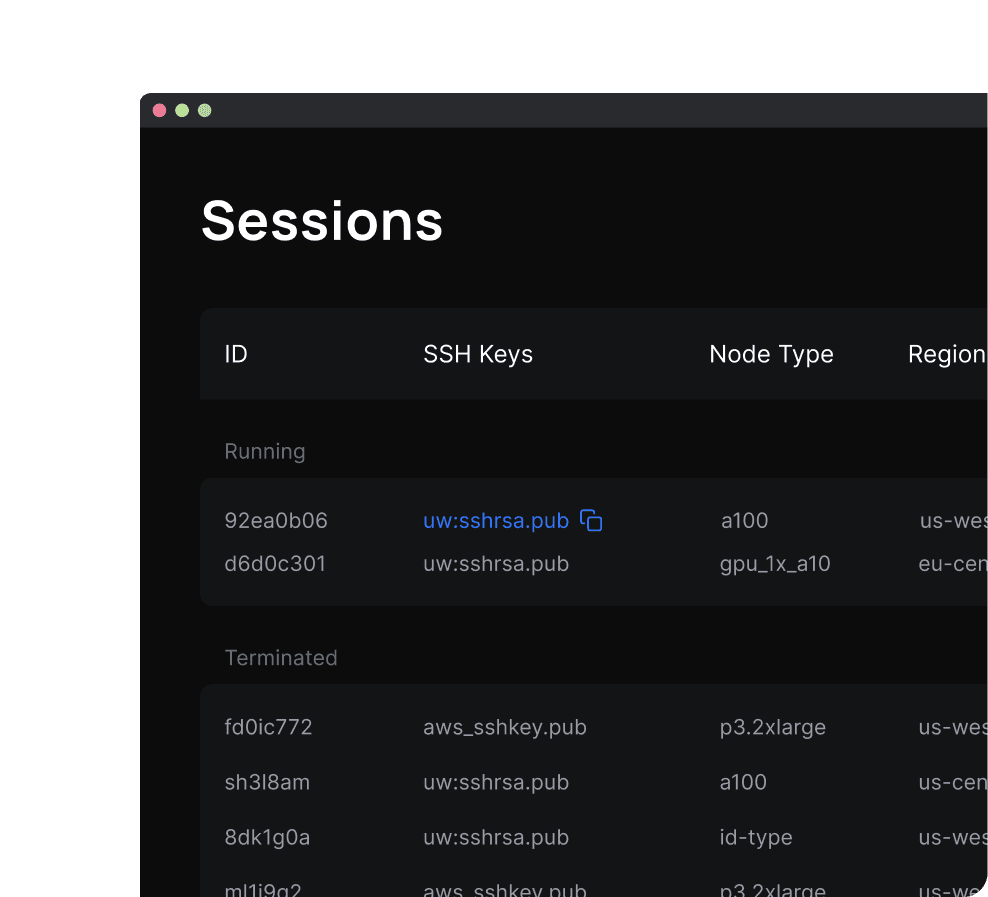
Unweave Dashboard
If you prefer a more visual interface, everything you can do with the CLI the Unweave Dashboard supports too.